
반응형
- OS의 메모리 관리 부분 설계 시 3가지 기본적인 선택 영역
- 가상 메모리 기술을 사용할지 여부
- 페이징, 세그먼테이션 혹은 세그먼테이션/페이징 결합의 사용 여부
- 메모리 관리와 관련된 알고리즘 선택 ⇒ OS 영역(S/W)
- 가상 메모리를 위한 OS 정책의 설계 이슈는 성능 ⇒ 가상 메모리의 성능은 Page Fault 발생과 관련
- 어떤 페이지를 교체할 것인지 결정
- 페이지를 Swap-out, Swap-in하기 위한 I/O 발생
- I/O가 진행될 동안 스케쥴링 발생
- 프로세스 교환
반입 정책 (Fetch Policy)
⇒ 각 페이지를 언제 실 메모리로 적재할지 결정하는 정책
요구 페이징 (Demanding Policy)
- 해당 페이지에 포함된 하나의 논리 주소가 참조되었을 때 적재함
- 프로세스 수행 시작 초기에 많은 페이지 폴트 발생
- 참조 지역성에 의해 시간이 지나면 페이지 폴트 횟수가 떨어짐
- 대부분의 OS에서 사용
선 반입 (Prepaging)
- 페이지 폴트에 의해 요구된 페이지 이외의 페이지들로 적재함
- 한 프로세스의 페이지들이 보조기억장치에 연속적으로 저장되어 있을 경우, 그들을 한꺼번에 반입하는 것이 효율적임 ⇒ 공간 지역성, 연속 페이지!
- 검색시간, 회전지연시간을 줄이기 위한 방안
- 추가 반입된 페이지들이 참조되지 않는다면 비효율적
- 프로그램 수행을 시작할 때나 페이지 폴트 발생시 적용할 수 있음
- 선 반입된 비용이 해당 페이지 폴트를 처리하는 비용보다 작다면 사용할만함
⇒ 선 반입 Cost < Page Fault Cost = GOOD!
배치 정책 (Placement Policy)
- 세그먼테이션의 경우 외부 단편화를 찾거나 빈 자리를 채우는 등 중요한 설계 이슈
⇒ But. 순수 페이징이나 세그먼테이션/페이징 결합의 경우 페이지는 다 똑같기 때문에 별도의 알고리즘이 필요 없다.
교체 정책 (Replacement Policy)
- 새로운 페이지를 반입하기 위해 현재 실 메모리에 적재된 페이지들 중 어떤 페이지를 교체할 것인지 결정
⇒ 목표 : 가까운 미래에 참조될 가능성이 가작 적은 페이지를 교체해야 한다.
교체 정책과 관련된 이슈
- 고려 대상 페이지 중에서 어떤 페이지를 교체 대상으로 선택할 것인가?
- 활동 중인 각 프로세스에게 얼마나 많은 프레임을 할당할 것인가?
- 교체 페이지로 고려될 대상을, 페이지 폴트를 발생시킨 프로세스의 페이지들로 한정시킬 것인가? 아니면 실 메모리 상의 모든 페이지로 확대할 것인가?
어떤 페이지를 교체 대상으로 선택할 것인가?
- 가장 이상적인 결정은 가까운 미래에 다시 참조될 가능성이 가장 적은 페이지를 선택하여 교체하는 것.
- 과거의 참조 형태와 가까운 미래의 참조 패턴 간에 높은 상관 관계가 있다고 밝혀짐
- 교체 정책이 정교할수록, 그 구현에 소요되는 H/W나 S/W 비용이 더 커짐
최적 (Optimal) 정책
- 미래에 가장 오랫동안 참조되지 않을 페이지를 교체
- 가장 적은 페이지 폴트를 발생시킴
- 구현 불가!
- 구현 가능한 알고리즘을 평가하기 위한 표준으로 이용됨
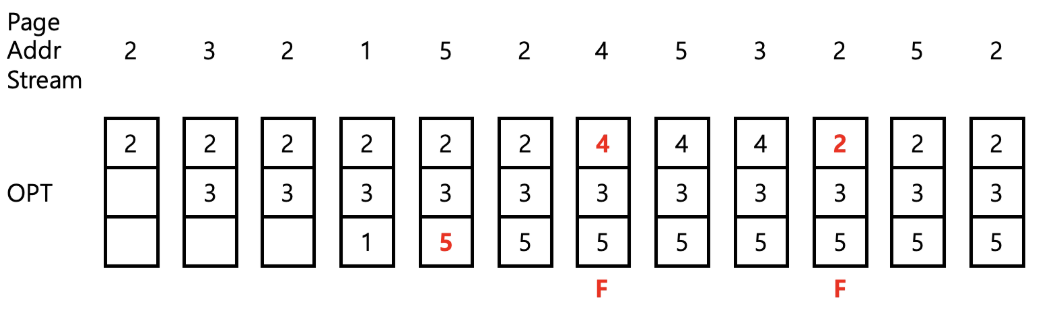
- 첫 번째 Page Fault : Page Addr Stream을 봤을 때, 미래에 1이 사용되지 않으므로 교체 대상
- 두 번째 Page Fault : 미래에 2가 제일 늦게 사용됨
- 세 번째 Page Fault : 미래에 4는 사용되지 않음
⇒ Page Fault 3회 발생
LRU (Least Recently Used) 정책
- 가장 오랫동안 참조되지 않은 실 메모리 상의 페이지를 교체
- 최적 정책에 근접하는 성능
- 구현하기 어렵고 오버헤드가 큼
- 페이지마다 참조시간을 유지시키는 방법
- 페이지 번호를 갖는 스택(Stack)을 유지하는 방법

⇒ 가장 오래된 것 교체
⇒ Fage Fault 총 4회 발생

- 참조되는 페이지 번호를 위로 올림
- Page Fault 발생시, 참조되는 페이지 번호를 Top에 두고, 오래된 페이지 번호를 제거(Pop)
⇒ Page Fault 총 4회 발생
FIFO (First-In First-Out) 정책
- 실 메모리로 반입된 페이지 중 가장 오래된 페이지 교체
- 순환 버퍼 상의 라운드로빈 방식으로 제거 ⇒ 구현이 쉬움
- 가장 오래 있었던 페이지는 많은 경우에 프로그램 수행 과정 내내 집중적으로 이용되는 코드나 데이터 영역일 수 있다.
- 2와 5페이지는 자주 참조되는 페이지임을 인식하지 못함
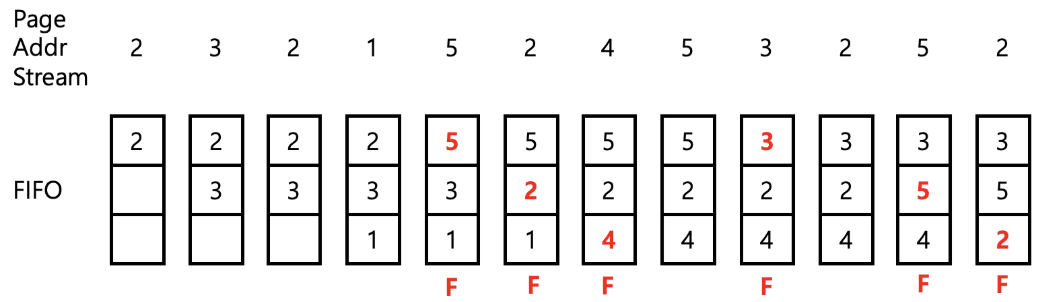
- 첫 번째 Page Fault : 2가 가장 오래됨
- 두 번째 Page Fault : 3이 가장 오래됨
- 세 번째 Page Fault : 1이 가장 오래됨
- 네 번째 Page Fault : 5가 가장 오래됨
- 다섯 번째 Page Fault : 2가 가장 오래됨
- 여섯 번째 Page Fault : 4가 가장 오래됨
⇒ Page Fault 총 6회 발생
클럭 (Clock) 정책 - 1
- 프레임 별로 사용 비트(Use bit) 연계
- 요구 페이징에 의해 처음 적재시 1 ⇒ 참조될 때마다 1로 설정
- 페이지를 적재한 프레임들이 환형으로 배치되어 있다고 간주하고, 첫 교체 후보를 가리키는 포인터를 설정
- 시계 방향으로 포인터를 이동시키면서 포인터가 가리키는 프레임 중 Use bit가 0인 첫 프레임 상의 페이지를 교체
- Use bit가 1인 경우, 그 값을 0으로 변경하고 다음 프레임으로 이동함
⇒ Use bit는 Page Table Entry의 Access bit (5번째)
⇒ Pointer와 Use bit만 관리하면 된다.

*는 Use bit이 1
- Use bit가 0인 것이 없으면 Pointer가 가리키는 것을 교체 (한 바퀴 돌고 모두 0으로 변경)
- Use bit가 0인 것은 교체 대상
- Use bit가 1이면 0으로 바꾸고 이동
- Use bit가 0이면 교체 대상
- 모든 버퍼의 Use bit가 1이면, 포인터가 한 바퀴 돌면서 0으로 바꾸고 원래 위치의 프레임에 적재된 페이지 교체
⇒ Page Fault 총 5회 발생
Page 교체 알고리즘의 성능 비교
⇒ OPT > LRU > CLOCK > FIFO
⇒ 단, 프레임이 많아질수록 성능 차이가 없다.
페이지 버퍼링 (Buffering)
- 교체 대상으로 선택된 페이지를 즉시 메모리에서 제거하지 않고 어느 정도 기간 동안 실 메모리 상에서 유지
- 가용 페이지 버퍼 : 메모리에 적재되어 변경되지 않은 채 교체된 페이지 저장
- 변경 페이지 버퍼 : 메모리에 적재되어 변경된 교체된 페이지 저장
- 페이지가 디스크에 기록될 경우 해당 페이지를 가용 페이지 버퍼로 이동
- 페이지 버퍼링의 이점
- 실제로 교체되기 이전에 참조될 경우 적은 비용으로 페이지 폴트 해결 가능
- 변경 페이지들에 대한 클러스터 I/O가 가능하여 I/O 연산의 회수 감소
적재집합 관리
적재집합의 크기 (Resident Set Size)
- 적재집합 : 특정 시점에 실 메모리에 적재되어 있는 프로세스의 페이지 집합
- OS는 각 프로세스에게 얼마나 많은 실 메모리(페이지 프레임의 수)를 할당할지 결정해야 함
- 고려사항 : 다중 프로그래밍 정도
- 한 프로세스에게 할당된 실 메모리의 양이 적을수록, 임의의 시점에 실 메모리에 많은 수의 프로세스가 적재됨 ⇒ 할당된 프레임의 수 감소 = 멀티 프로그래밍 정도 상승
- 특정 시점에 적어도 하나 이상의 준비 상태 프로세스가 존재할 가능성을 높여, 스와핑으로 인한 시간적 손실을 절감할 수 있다.
- 고려사항 : 페이지 폴트 발생률
- 실 메모리 상에 적재된 한 프로세스의 페이지 수가 상대적으로 작으면, 지역성의 원리에도 불구하고 페이지 폴트 발생률 증가
- 어떤 한계를 넘어서면, 프로세스에 페이지 프레임이 추가 할당되더라도 지역성의 원리에 의해 그 프로세스의 페이지 폴트 발생률에 큰 영향이 없음

- 고정 할당 (Fixed Allocation) 정책
- 각 프로세스에게 고정 개수의 페이지 프레임을 할당하여 수행시킴
- 프로세스 수행 중에 페이지 폴트가 발생하면 그 프로세스에 할당된 페이지 중 하나가 새로운 페이지로 교체됨
- 가변 할당 (Variable Allocation) 정책
- 프로세스 생존 기간 동안 각 프로세스에 할당된 프레임 수의 변경을 허용
- 어떤 프로세스에 페이지 폴트 발생률이 증가하면 프레임을 추가 할당하고, 페이지 폴트 발생률이 현저히 낮으면 할당된 프레임을 회수함
- 교체 범위 (Replacement Scope)
- 가용 프레임이 없을 때, 페이지를 적재할 프레임 선택의 범위(Scope)를 결정하는 정책
- 지역 교체 (Local replacement) 정책
- 페이지 폴트를 발생시킨 프로세스의 적재집합 내에서 교체 대상을 선택
- 전역 교체 (Global replacement) 정책
- 실 메모리 상의 모든 페이지 중에서 교체 대상을 선택
교체 범위와 적재집합 크기 간의 관련성
| 지역 교체 | 전역 교체 | |
| 고정 할당 | - 한 프로세스에게 할당된 프레임 수 고정 - 해당 프로세스에게 할당된 프레임 중에서 교체될 페이지 선택 |
- 불가 |
| 가변 할당 | - 프로세스에게 할당된 프레임의 수는 프로세스의 작업집합을 유지하기 위해 수시로 변경 가능 - 해당 프로세스에게 할당된 프레임 중에서 교체될 페이지 선택 |
- 실 메모리의 모든 프레임 중에 교체될 페이지를 선택하여, 이로 인해 프로세스의 적재집합 크기 변경 |
고정 할당 / 지역 범위
- 한 프로세스에게 할당된 프레임 수 고정
- 해당 프로세스에게 할당된 프레임에 적재된 페이지들 중에서 교체될 페이지 선택
- 한 프로세스에게 할당할 프레임 수를 미리 결정해야 함
- 할당량이 너무 적을 경우, 페이지 폴트 발생률이 높아짐 ⇒ 처리기 활용률 감소
- 할당량이 많아질수록, 스와핑으로 소모되는 시간 증가 ⇒ 처리기 활용률 감소
가변 할당 / 전역 범위
- 구현이 쉬움 ⇒ 많은 OS에 의해 채택
- OS는 가용 프레임 리스트(Free Frame List)를 유지
- 페이지 폴트 발생시, 가용 프레임이 프로세스의 상수 집합에 의해 추가됨
- 페이지 폴트를 발생시키고 있는 모든 프로세스는 작업집합의 크기가 점진적으로 증가함
- 가용 프레임이 없으면 어캄? ⇒ OS는 현재 메모리에 있는 임의의 프로세스에 속한 하나의 페이지를 선택해야 함
- 이 접근의 어려움은 어느 프로세스로부터 교체 대상 페이지를 선택할 것인지 규칙이 없음
- 프레임을 빼앗긴 프로세스는 작업집합의 크기가 줄어들어 페이지 폴트가 증가할 가능성이 있음
- 잘못된 페이지 선택 문제 해소 방안 ⇒ 페이지 버퍼링
가변 할당 / 지역 범위
- 프로세스를 처음 적재할 때, 어떤 척도에 의거하여 어느 정도의 프레임들을 적재집합으로 할당
- 페이지 폴트 발생시 해당 프로세스의 적재집합 내에서 교체
- 수시로, 프로세스에 대한 할당량을 재평가하여 프레임 할당량을 증감
- 핵심 요소
- 적재집합 크기를 결정하기 위해 사용되는 기준
- 변경 시점을 결정하기 위해 사용되는 기준
- 대표적 전략
- 작업집합 전략
- PFF (Page Fault Frequency)
- VSWS (Variable-Interval Sampled Working Set)
작업집합 전략
- 특정 프로세스 (페이지 수 N)에 대한 작업집합 W(t, Δ**)**
- 해당 프로세스가 가상 시간의 시점 t-Δ부터 t까지 참조한 페이지들의 집합임
- 가상 시간은 특정 프로세스에 의해 생성된 i번째 가상 주소가 페이지 r[i]에 포함된다고 할 때, 이를 1로 함
- Δ는 프로세스를 관찰하기 위한 가상 시간 상의 작업집합 창(Window)임
- 작업집합의 크기는 창의 크기에 대해 비감소 함수임 ⇒ W(t, Δ+1) ≥ W(t, Δ)
- 작업집합은 시간의 함수임 ⇒ 1 ≤ |W(t, Δ)| ≤ min(Δ, N)
⇒ 창 크기 증가 = 작업집합 증가
- Δ와 프로세스의 작업집합

⇒ But, 작업집합이 언제 변할지 예측 불가
- 작업집합 관리 방법 (적재집합의 크기를 결정하는 전략의 지침)
- 각 프로세스의 작업집합을 모니터링한다.
- 주기적으로 프로세스의 적재집합 중 작업집합에 포함되지 않은 페이지들을 제거한다. ⇒ 프레임 회수(LRU 정책)
- 프로세스는 실 메모리에 그 작업집합이 있을 때 (적재집합이 작업집합을 포함할 때)만 수행된다.
- 문제점
- 각 프로세스의 작업집합 모니터링 비용이 비현실적이다.
- 최적의 Δ값이 알려져있지 않고, 어떤 경우라도 가변적이다. ⇒ 어느 시간에 발생할지 모름
작업집합 : 전략의 근사 전략
- 전략 : 작업집합이 아니라 페이지 폴트 발생률을 모니터링함
- 한 프로세스의 페이지 폴트 발생률이 하위 임계치보다 낮으면 적재집합을 줄임
- 페이지 폴트 발생률이 상위 임계치보다 높으면 적재집합의 크기를 증가시킴
- Page Fault 발생률
- 낮다 : 프레임 회수
- 높다 : 프레임 할당
- PFF (Page Fault Frequency) 전략
- 각 페이지와 연관된 사용 비트(Use bit)를 페이지가 참조할 때마다 1로 설정
- 페이지 폴트 발생 간의 시간은 페이지 폴트 발생률과 역관계임
- 페이지 폴트가 발생될 경우, 프로세스는 직전의 페이지 폴트 발생 시점으로부터 경과된 가상 시간(페이지 참조 카운터)을 측정함
- 경과 시간이 임계치보다 작은 경우 해당 프로세스의 적재집합에 한 페이지를 추가
- 그렇지 않을 경우 사용 비트가 0인 모든 페이지를 적재집합에서 제거시켜 적재집합을 축소
- 제거되지 않은 페이지의 사용 비트는 모두 0으로 설정
- 작업집합이 전이되는 과도 기간에 적재집합을 효과적으로 제어하지 못함
- 이 전략을 페이지 버퍼링으로 보완하면 성능이 좋아짐
클리닝 정책 (Cleaning Policy)
- 변경된 페이지들을 언제 보조기억장치에 기록할 것인지 결정하는 정책
- 요구 클리닝 (Demand Cleaning) : 각 페이지가 교체 대상으로 선택되었을 때 기록함
- 선클리닝 (Pre-cleaning) : 해당 페이지 프레임이 요구되기 전에 변경된 페이지들을 기록함 (일괄 등록 가능, I/O 장치 효율성에 기여) ⇒ 미리 예측
- 페이지 버퍼링과 접목하여 적용할 경우 효과적
- 변경된 페이지가 교체 후보로 선택되면 변경 페이지 버퍼에 연결시킨 후, 주기적으로 일괄 기록한 후 가용 페이지 버퍼로 이동
- 페이지 교체시 가용 프레임이 없을 경우, 가용 페이지 버퍼 상의 프레임을 할당하여 적재
- 기록되기 이전에 참조될 경우 기록/적재 없이 재활용 가능
- 페이지 교체시 가용 페이지 버퍼 상의 프레임을 이용하므로, 교체 당시 기존 페이지의 기록 작업은 없음
부하 제어 (Load Control)
- 실 메모리에 적재될 프로세스 수를 결정하는 정책

다중 프로그래밍 수준 조절
- 작업집합/PFF
- 적재집합이 충분히 갖추어진 활성 프로세스만 수행을 허용하므로, 그 관리 과정에서 자동/동적으로 활성 프로세스의 수를 결정함
- L=S 규범
- 폴트 간 평균시간 L과 폴트 처리에 필요한 평균시간 S가 일치되게 다중 프로그래밍 수준을 조절함 (처리기 활용도 극대화)
- 50% 규범
- 페이징 장치의 활용도가 50%로 유지함 (처리기 활용도 극대화)
- 클록 정책의 변형
- ‘바늘’의 스캔 속도가 너무 빠르면(상위 임계치보다 높음) 다중 프로그래밍 수준을 낮추고, 너무 느리면 높이는 방법 적용
프로세스 보류
- 다중 프로그래밍의 수준을 낮추기 위해 어떤 프로세스를 보류(Suspension)시킬지 결정해야함
- 보류 대상으로 고려할만한 프로세스
- 최저 우선순위 프로세스 : 스케쥴링 정책과 일관성 유지
- 폴트 발생 프로세스 : 작업집합 적재 가능성이 적어 보류 시 입게될 손해가 최소일 가능성 (직접적 유익 : 바로 블록될 프로세스를 블록시키는 것이므로, 페이지 교체나 I/O 비용 절감)
- 가장 최근에 활성화된 프로세스 : 작업집합 학보 가능성 최소
- 최소 적재집합을 가진 프로세스 : 미래의 재적재 비용을 최소화하지만, 지역성이 강한 프로세스에게 불리
- 가장 큰 프로세스 : 가장 많은 가용 프레임 확보, 추가 보류의 필요성 감소
- 잔여 수행 윈도우가 가장 큰 프로세스 : 최소 처리시간 우선(Shortest-Processing-Time-First) 스케쥴링과 일관성 유지
반응형
